Оптическое распознавание ЦСл текстов (OCR)
Получить текст с печатного источника в электронном виде можно с помощью специальных программ оптического распознавания текстов (OCR). В качестве такой программы весьма удобно использовать ABBYY FineReader.
Сканируйте оригинал с разрешением 300 dpi. Программа FineReader оптимизирована для работы именно с таким разрешением. При сканировании следует подбирать яркость, так, чтобы на полученном изображении, с одной стороны, буквы не были слишком "бледными", а, с другой стороны, не оказались слишком "жирными", и не проступали бы пятна. Подбор яркости (для "серого" изображения) можно доверить программе распознавания в автоматическом режиме.
1. Создание пользовательского языка и словаря
Настройка программы FineReader для сканирования церковнославянских текстов начинается с создания пользовательского языка. Для этого следует вызвать через меню "Сервис" окно редактора языков, затем создать на базе русского языка язык ЦСл. Следующим этапом является определение алфавита языка, в основу которого положен формат ![]() hip:
hip:
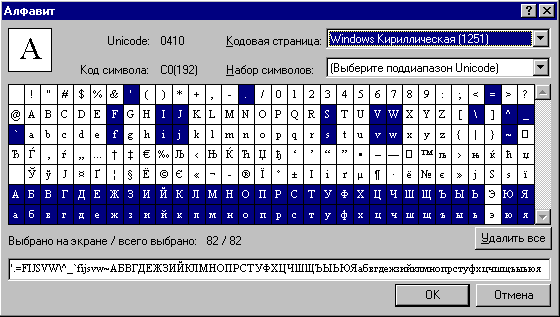
После чего определяются:
1) знаки препинания, примыкающие к началу слова: -[«
2) знаки препинания, примыкающие к концу слова: !"*,-.:;]»
3) знаки препинания, встречающиеся отдельно от слов: #*
Кроме того, следует задать пользовательский словарь. Словарь можно получить с сайта Библиотеки святоотеческой литературы отсюда. Для успешной работы со словарем необходимо добавить в начало файла строку следующего содержания:
DICTIONARY_PROPERTIES=USE_CONFIDENCE
Можно не создавать язык, а использовать его из предложенного пакета (пакет работает на версиях ABBYY FineReader 6.0 и выше). Тогда в окне редактора языков следует указать путь к этому пакету в графе "путь к пользовательским языкам и словарям".
2. Редактирование текстов в формате HIP
Для набора и редактирования текстов в формате ![]() hip требуется нестандартная раскладка клавиатуры. Один из вариантов системной раскладки для Windows рассматривается в статье Раскладки для редактирования церковнославянских текстов, где он доступен для скачивания.
hip требуется нестандартная раскладка клавиатуры. Один из вариантов системной раскладки для Windows рассматривается в статье Раскладки для редактирования церковнославянских текстов, где он доступен для скачивания.
3. Обучение эталона
Для того, чтобы получить возможность распознавать тексты на церковнославянском, нужно обучить пользовательский эталон (если не действуют имеющиеся) через вкладку Сервис→ Опции→ Распознавание→ Обучение. Предварительно отключите флаг "Использовать встроенные эталоны".
При обучении не рекомендуется обучать одну и ту же лигатуру слишком много раз (достаточно, как правило, 3-4 раза). После того, как основной набор языка уже обучен, можно прогнать программу по нескольким страницам, затем найти те лигатуры, которые оказались не обучены. Чтобы правильно их дообучить, нужно выделить слово (содержащее лигатуру) вместе с несколькими соседними, в отдельный блок, затем распознать эти блоки с обучением. Чтобы повторно не обучать символы, можно использовать кнопку "Пропустить".
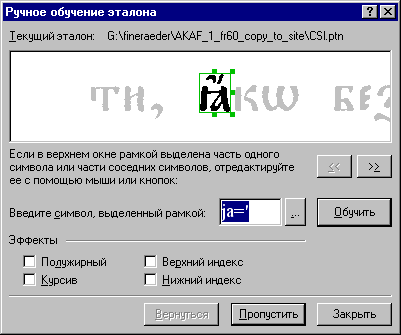
Большой эталон, рассчитанный на самые разные церковные издания, можно скачать с сайта Библиотеки святоотеческой литературы отсюда.
4. Распознавание
Перед распознаванием текстов отключите флаг "Очищать фон" во вкладке Сервис→ Опции→ Распознавание→ Тип страницы.
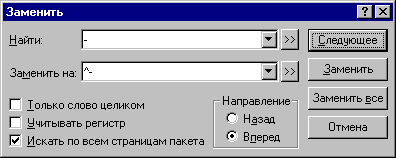
Если символы переносов в конце строк распознаны в виде дефисов "-", необходимо заменить их на знаки мягкого переноса.
6. Проверка
При проверке не рекомендуется использовать опцию "Останавливаться на неуверенно распознанных словах" (во вкладке Сервис→ Опции→ Проверка→ Установки), так как они будут встречаться в каждом слове. Проще просмотреть неуверенно распознанные слова или символы (которые выделяется синим цветом) в окне Текст.